





导入库并加载数据集
import time
import math
import numpy as np
import torch
from torch import nn, optim
import torch.nn.functional as F
import zipfile
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
(corpus_indices, char_to_idx, idx_to_char, vocab_size) = load_data_jay_lyrics()定义模型
PyTorch中的nn模块提供了循环神经网络的实现。下面构造一个含单隐藏层、隐藏单元个数为256的循环神经网络层rnn_layer。
num_hiddens = 256
# rnn_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens) # 已测试
rnn_layer = nn.RNN(input_size=vocab_size, hidden_size=num_hiddens)与上一节中实现的循环神经网络不同,这里rnn_layer的输入形状为(时间步数, 批量大小, 输入个数)。其中输入个数即one-hot向量长度(词典大小)。此外,rnn_layer作为nn.RNN实例,在前向计算后会分别返回输出和隐藏状态h,其中输出指的是隐藏层在各个时间步上计算并输出的隐藏状态,它们通常作为后续输出层的输入,也就是说,一次性计算出所有时间步的隐藏层的状态。需要强调的是,该“输出”本身并不涉及输出层计算,形状为(时间步数, 批量大小, 隐藏单元个数)。而nn.RNN实例在前向计算返回的隐藏状态指的是隐藏层在最后时间步的隐藏状态:当隐藏层有多层时,每一层的隐藏状态都会记录在该变量中。关于循环神经网络(以LSTM为例)的输出,可以参考下图。
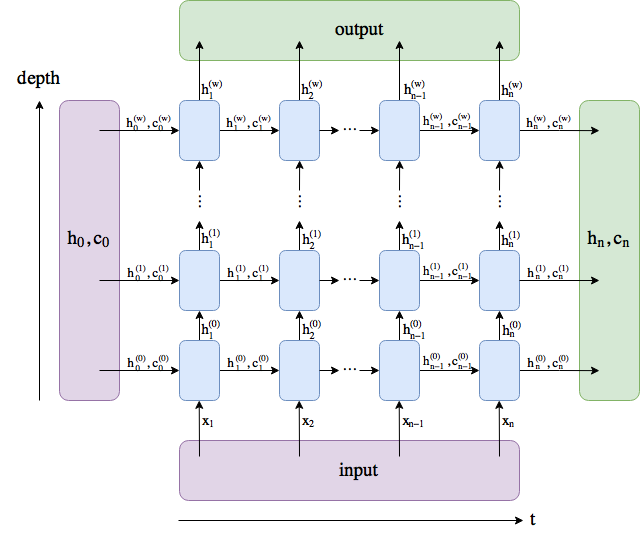
输出形状为(时间步数, 批量大小, 隐藏单元个数),隐藏状态h的形状为(层数, 批量大小, 隐藏单元个数)。
num_steps = 35
batch_size = 2
state = None接下来继承Module类来定义一个完整的循环神经网络。它首先将输入数据使用one-hot向量表示后输入到rnn_layer中,然后使用全连接输出层得到输出。输出个数等于词典大小vocab_size。
class RNNModel(nn.Module):
def __init__(self, rnn_layer, vocab_size):
super(RNNModel, self).__init__()
self.rnn = rnn_layer
self.hidden_size = rnn_layer.hidden_size * (2 if rnn_layer.bidirectional else 1)
self.vocab_size = vocab_size
self.dense = nn.Linear(self.hidden_size, vocab_size)
self.state = None
def forward(self, inputs, state): # inputs: (batch, seq_len)
# 获取one-hot向量表示
X = to_onehot(inputs, self.vocab_size) # X是一个长度为seq_len的列表,每个元素形状为(batch, vocab_size)的矩阵
Y, self.state = self.rnn(torch.stack(X), state) # stack函数将X这个列表转换为矩阵,即形状为(seq_len, batch, vocab_size)的矩阵
# Y的形状为(seq_len, batch, hidden_size)
# 全连接层会首先将Y的形状变成(num_steps * batch_size, num_hiddens),它的输出
# 形状为(num_steps * batch_size, vocab_size)
output = self.dense(Y.view(-1, Y.shape[-1]))
return output, self.state训练模型
定义一个预测函数。这里的实现区别在于前向计算和初始化隐藏状态的函数接口。
def predict_rnn_pytorch(prefix, num_chars, model, vocab_size, device, idx_to_char,
char_to_idx):
state = None
output = [char_to_idx[prefix[0]]] # output会记录prefix加上输出
for t in range(num_chars + len(prefix) - 1):
X = torch.tensor([output[-1]], device=device).view(1, 1)
if state is not None:
if isinstance(state, tuple): # LSTM, state:(h, c)
state = (state[0].to(device), state[1].to(device))
else:
state = state.to(device)
(Y, state) = model(X, state)
if t < len(prefix) - 1:
output.append(char_to_idx[prefix[t + 1]])
else:
output.append(int(Y.argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])接下来实现训练函数。算法同上一节的一样,但这里只使用了相邻采样来读取数据。
def train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes):
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
model.to(device)
state = None
for epoch in range(num_epochs):
l_sum, n, start = 0.0, 0, time.time()
data_iter = data_iter_consecutive(corpus_indices, batch_size, num_steps, device) # 相邻采样
for X, Y in data_iter:
if state is not None:
# 使用detach函数从计算图分离隐藏状态, 这是为了
# 使模型参数的梯度计算只依赖一次迭代读取的小批量序列(防止梯度计算开销太大)
if isinstance (state, tuple): # LSTM, state:(h, c)
state = (state[0].detach(), state[1].detach())
else:
state = state.detach()
(output, state) = model(X, state) # output: 形状为(num_steps * batch_size, vocab_size)
# Y的形状是(batch_size, num_steps),转置后再变成长度为
# batch * num_steps 的向量,这样跟输出的行一一对应
y = torch.transpose(Y, 0, 1).contiguous().view(-1)
l = loss(output, y.long())
optimizer.zero_grad()
l.backward()
# 梯度裁剪
grad_clipping(model.parameters(), clipping_theta, device)
optimizer.step()
l_sum += l.item() * y.shape[0]
n += y.shape[0]
try:
perplexity = math.exp(l_sum / n)
except OverflowError:
perplexity = float('inf')
if (epoch + 1) % pred_period == 0:
print('epoch %d, perplexity %f, time %.2f sec' % (
epoch + 1, perplexity, time.time() - start))
for prefix in prefixes:
print(' -', predict_rnn_pytorch(
prefix, pred_len, model, vocab_size, device, idx_to_char,
char_to_idx))使用和上一节实验中一样的超参数(除了学习率)来训练模型。
num_epochs, batch_size, lr, clipping_theta = 250, 32, 1e-3, 1e-2 # 注意这里的学习率设置
pred_period, pred_len, prefixes = 50, 50, ['分开', '不分开']
train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)输出:
epoch 50, perplexity 10.340747, time 0.03 sec
- 分开始的美 还是我 一个人 一个 我想要 一个走 一枝杨柳 你在那里 在小村外的溪边河口默默默默默默默默
- 不分开不多 有 你的手不放开 不要再这样打我妈妈 想要你的微笑 我想你的爱写 我想要再想你 我 你的手不放
epoch 100, perplexity 1.279130, time 0.03 sec
- 分开 一直到我妈妈 说不了很久了听怎么就是我想你和汉堡 我想要你的微笑每天都能看到 我知道这里很美但家
- 不分开不 我不要再想你 不 我不多太多 我想你这样的听不知不这 我想要和你怎么面对你 爱你在我妈不知道这
epoch 150, perplexity 1.059548, time 0.03 sec
- 分开 了过去种慢 从小 大有 印地安老斑鸠 腿短毛不多 几天都没有喝水也能活 脑袋瓜有一点秀逗 猎物死
- 不分开不 我不能够远远看著 这些我 做得到 但那个人已经不是我 没有你在 我有多难熬 没有你在我有多难熬
epoch 200, perplexity 1.031833, time 0.04 sec
- 分开 了过云种 一直在身边的让力还说分边 手过心疼的玄家岩 别天的手在会运做将到 泪那她养的黑猫笑起
- 不分开不 我不要再想你看爱 你 一起看到现 一直到身边 我爱能的片味语 爱情在的形口语著 风什么我
epoch 250, perplexity 1.019352, time 0.03 sec
- 分开 了过云层 我试著努力向你奔跑 爱才送到 你却已在别人怀抱 就是开不了口让她知道 我一定会呵护著你
- 不分开不 我不要再想你 爱 走的太快 像龙卷风 不能承受我已无处可躲 我不要再想 我不要再想 我不 我不
Comments | NOTHING